Barnan Das
Imbalanced Class Distribution
As machine learning techniques mature and are used to tackle complex scientific problems, challenges arise such as the imbalanced class distribution problem, where one of the target class labels is under-represented in comparison with other classes. Existing oversampling approaches for addressing this problem typically do not consider the probability distribution of the minority class while synthetically generating new samples. As a result, the minority class is not well represented which leads to high misclassification error. We introduce wRACOG, a Gibbs sampling-based oversampling approach to synthetically generating and strategically selecting new minority class samples. The Gibbs sampler uses the joint probability distribution of data attributes to generate new minority class samples in the form of a Markov chain. wRACOG iteratively learns a model by selecting samples from the Markov chain that have the highest probability of being misclassified. We validate the effectiveness of wRACOG using five UCI datasets and one new application domain dataset. A comparative study of wRACOG with three other well-known resampling methods provides evidence that wRACOG offers a definite improvement in classification accuracy for minority class samples over other methods.
Overlapping Classes
The class imbalance problem is a well-known classification challenge in machine learning that has vexed researchers for over a decade. Under-representation of one or more of the target classes (minority class(es)) as compared to others (majority class(es)) can restrict the application of conventional classifiers directly on the data. In addition, emerging challenges such as overlapping classes, make class imbalance even harder to solve. Class overlap is caused due to ambiguous regions in the data where the prior probability of two or more classes are approximately equal. We are motivated to address the challenge of class overlap in the presence of imbalanced classes by a problem in pervasive computing. Specifically, we are designing smart environments that perform health monitoring and assistance. Our solution, ClusBUS, is a clustering-based undersampling technique that identifies data regions where minority class samples are embedded deep inside majority class. By removing majority class samples from these regions, ClusBUS preprocesses the data in order to give more importance to the minority class during classification. Experiments show that ClusBUS achieves improved performance over an existing method for handling class imbalance.
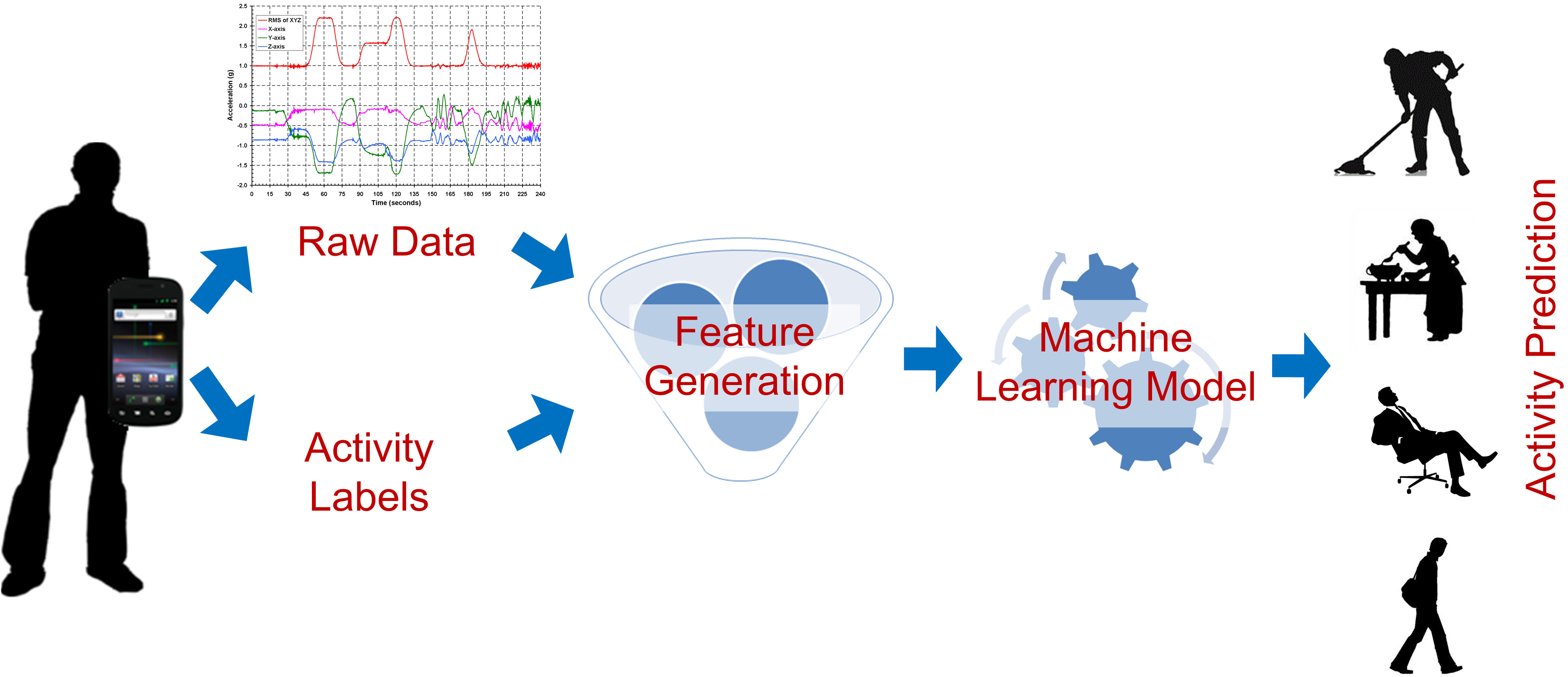
Smart Phone-Based Locomotive Activity Recognition
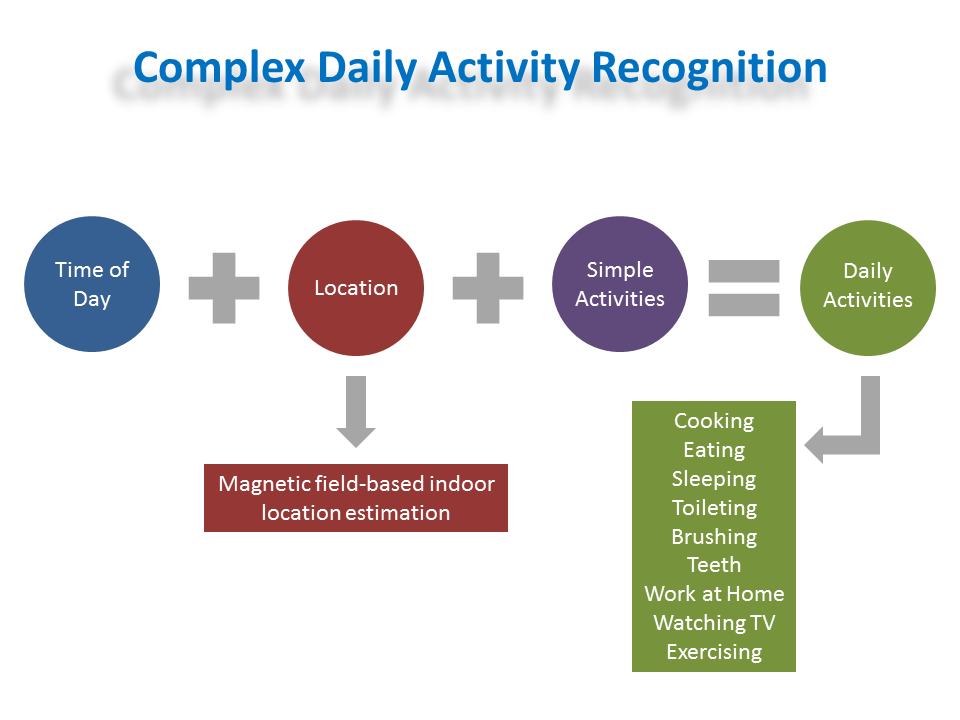
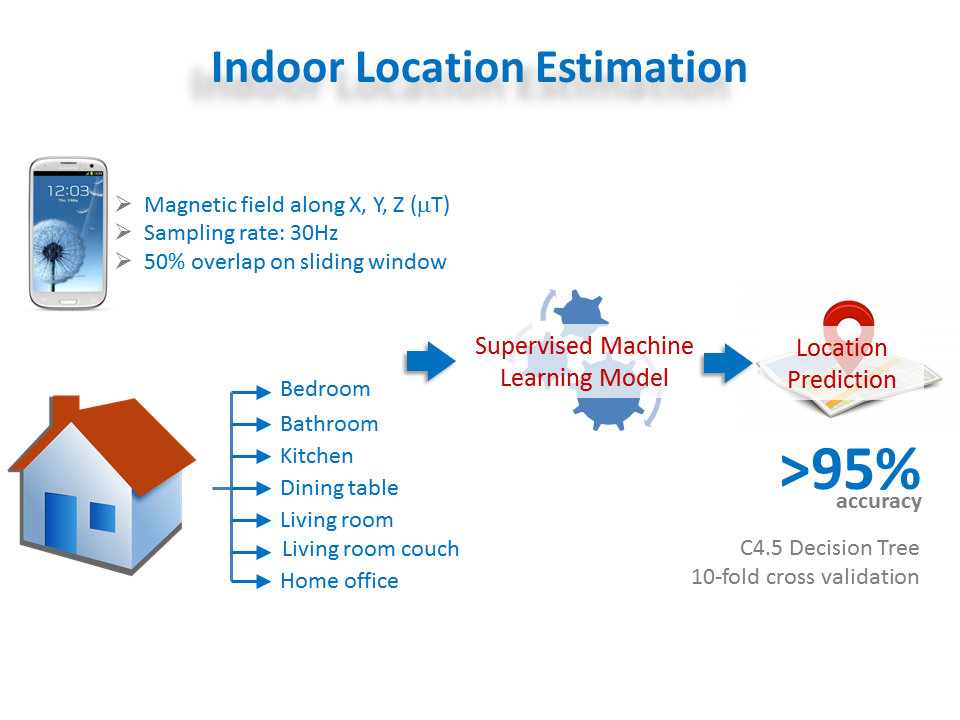
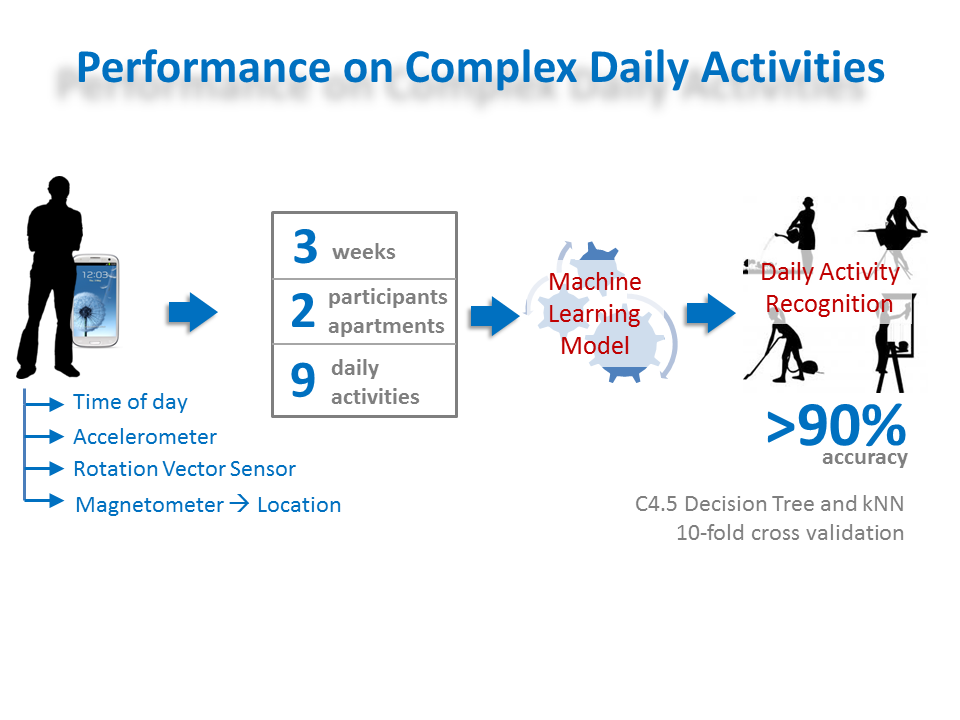
Smart Phone-Based Complex Daily Activity Recognition